All Post
AI Fintech Toolkit: our own AI built to accelerate fintech delivery


The honest problem with AI coding tools
You've probably seen the headlines: AI can now write code. Faster, cheaper, around the clock. For most industries, and specially in early stage companies, that's an unambiguous win.
In fintech, however, it's more complicated.
Here's the thing about a generic AI model: ask it to “build a payment system” and it will confidently build one. The code will look right. The demo will work.
But it won't be your payment system: the one that has to handle real money, real customers, and real regulators without breaking the first time something unexpected happens.
This difference is everything. A generic AI agent doesn't know that your business operates in multiple currencies, or that one of your payment partners requires an extra security step above a certain amount, or that logging the wrong field could put you in violation of compliance rules overnight. It doesn't know that if a customer's connection drops and they tap “Pay” twice, your system should charge them once, not twice.
These aren't edge cases. They're the everyday reality of moving money, and a generic model will get them wrong fluently and at speed, which is the worst combination of all.
This is why we don't just hand our engineers a generic AI assistant and call it a day. In a regulated, money-handling industry, fast without guardrails isn't a feature, it's a liability.
So we built our own. The AI Fintech Toolkit is what closes the gap between the generic AI you've heard about and the specialized, fintech-aware system your product actually needs to be built on.
What the AI Fintech Toolkit actually is
The AI Fintech Toolkit is our internal toolkit for using AI across the full software lifecycle, from product discovery to production code, without losing the engineering rigor our clients depend on.
It is not a single tool. It's a curated stack of:
Domain-specific prompts and agents, tuned to fintech use cases (payments, KYC/KYB, ledgering, reconciliation, brokerage, BNPL, card issuing, multi-tenant access control, and so on).
A library of verified patterns and code templates, tested against the kinds of edge cases we've actually run into in production, including the failure cases.
Automated guardrails: checks that catch security, compliance, and quality issues, plus tests and documentation generated alongside the code so nothing ships unverified or unexplained.
A feedback loop where every reusable insight, pattern, or anti-pattern we encounter on a project gets fed back into the toolkit so the next project starts a step ahead.
In one line: it's how we let AI accelerate us without letting AI decide what "good" looks like.

What this changes for you
The headline benefit is simple: production-ready fintech code, faster, and without trading off the things you actually care about.
In practice, that means:
You get to market sooner. What used to take weeks of setup and scaffolding before the real product work started now takes days, and the prototype is production-ready from the ground up, not something we'll need to rebuild before launch.
Fewer compliance surprises. Things like PCI-DSS, sensitive-data handling, and audit trails are baked into the foundation we build on, not bolted on at the end when an audit is looming.
Code that reads well to anyone who needs to read it. Whether it's an auditor, a future engineer, or a new tech partner taking over, the work arrives documented, tested (including the cases that should fail), and consistent. Not a tangle that only the original author understands.
Senior engineers focused on the parts that matter. Instead of spending hours on plumbing the AI can produce in seconds, our team is focused on the decisions that shape your product: the integrations, the user experience, the trade-offs unique to your business.
A foundation that improves over time. Every engagement makes the toolkit a little sharper. The next thing we build for you (and the thing after that) starts from a stronger base than the one before.
For a founder or product owner, the practical takeaway is this: you get the speed advantage that AI promises, plus the kind of careful, regulated-industry engineering that fintech actually requires. You don't have to pick one.

(The general structure of the AI Fintech Toolkit)
What it is not
A few things worth being explicit about, because the AI hype cycle invites confusion:
It's not a code generator we point at a ticket and walk away. A senior engineer is always in the loop. The Toolkit makes them faster; it doesn't replace them.
It's not "vibe-coded" software. Every line that ships has been read, reviewed, tested, and reasoned about by a person who understands the domain.
It's not a black box. We can explain why the code looks the way it does, point to the pattern it came from, and show the checks it passed on the way in.
It's not a shortcut around real engineering. What carries between projects are principles, abstracted patterns, lessons learned, best practices. Each client's product is built fresh, on its own terms.
Why “AI alone” isn't enough in fintech
We talked at the top about why a generic AI falls short in fintech. Here's the more concrete version of that gap, for the technically curious.
Out-of-the-box AI is a generalist. It has read a lot, but it's been trained on the entire internet, most of which is not regulated financial software. So when it writes code, it produces something that looks like the average of everything it has seen. In fintech, the average isn't good enough.
It doesn't know your business's rules: which currencies you support, which payment networks you integrate with, which fields are sensitive, which operations have to be safe to retry, which thresholds trigger which compliance flows. It doesn't know your house style: the conventions, naming, error handling, and architectural decisions that keep a codebase coherent across dozens of engineers and dozens of features.
And critically, it has no way to verify what it just wrote. It will hand you a confident answer with the same energy whether the code is bulletproof or quietly broken. The Toolkit's job is to close all three of those gaps: domain knowledge, house style, and verification, so the AI's output is shaped by what fintech actually demands, not just by what code generally looks like on the internet.
How the Toolkit architecture actually works
For the more technical readers, here's how this plays out in practice. We think of the Toolkit as four layers, each one closing a gap that generic AI leaves open.
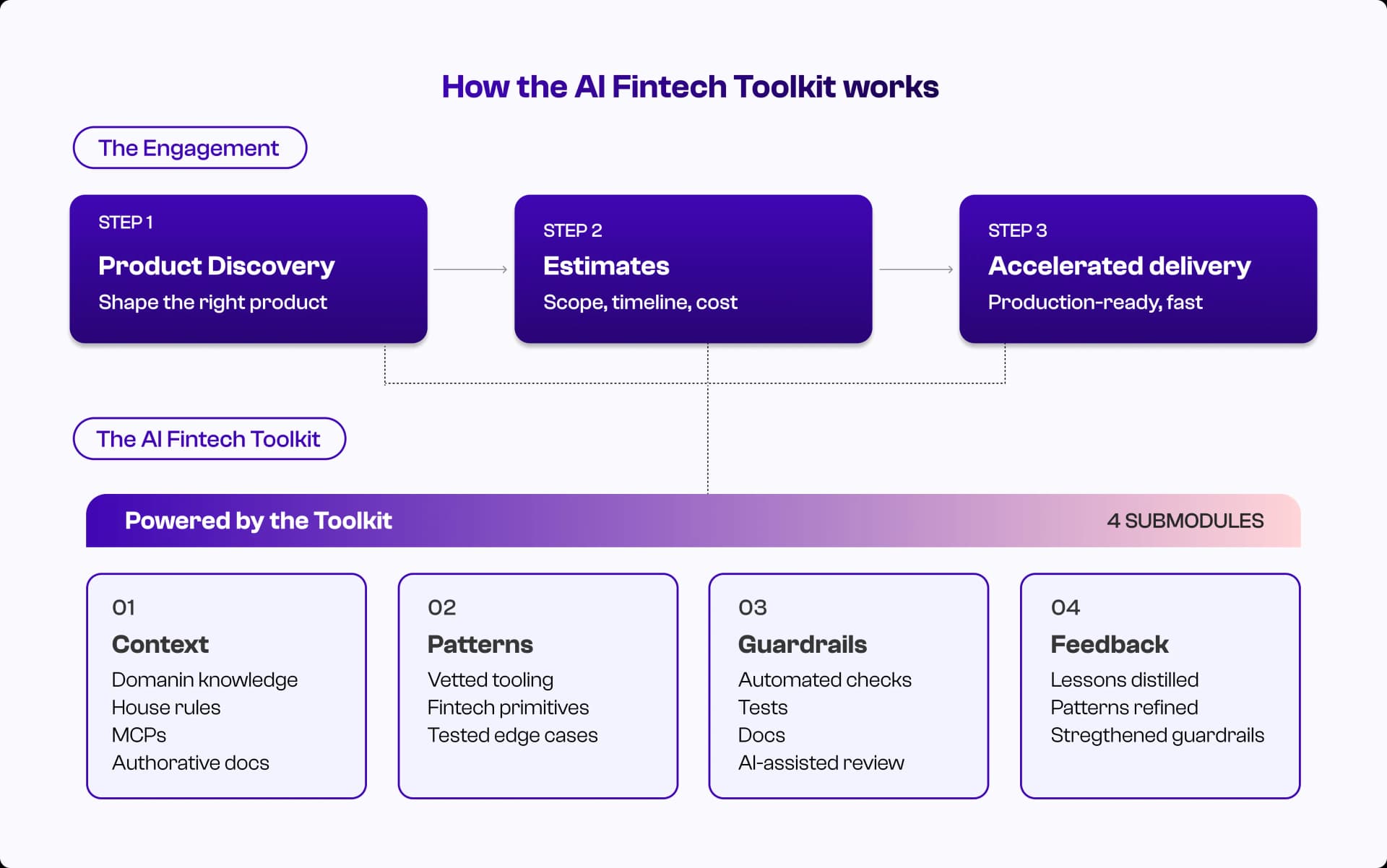
(How our AI Fintech Toolkit works)
1. Context layer: giving the model a memory it can trust
Foundation models are powerful but stateless. Every conversation starts from zero, with no awareness of how we build, what conventions we follow, or what the dominant tools in a given domain actually expect.
The Context layer fixes that. It pulls in, on demand:
Authoritative documentation from the big players in each domain: payment processors, KYC providers, brokerage APIs, ledger systems, card networks — surfaced through MCP servers and structured indexes so the model is reasoning over the current spec, not what it half-remembers from training.
Our house's rules: architectural conventions, naming standards, security policies, and the common domain models we use across fintech work (Account, Ledger, Transaction, Settlement, Payout, Tenant, Role).
Framework- and library-specific rules and tips: the gotchas, patterns, and “do this, not that” guidance we've accumulated for the stacks we use most.
When an engineer asks the Toolkit to scaffold a service, the model doesn't start from zero and doesn't hallucinate API contracts that don't exist. It starts from a pre-loaded understanding of how we build and how the tools it's integrating with actually work, which lets the output land much closer to production-ready on the first pass.
2. Pattern layer: vetted building blocks instead of improvised code
Some problems in fintech show up over and over: idempotency, retries with backoff, webhook signature verification, currency conversion with safe rounding, pagination over financial events, audit logging, soft-delete vs. tombstoning, reconciliation jobs, and (increasingly important as platforms scale) multi-tenant data isolation and fine-grained access control, where one buggy query can leak one merchant's data to another.
For each of these, we maintain reference implementations that have been:
Reviewed by senior engineers.
Tested against edge cases we've actually seen in production, with both positive and negative test cases (a pattern is only “vetted” once we've written down the cases where it should fail, not just where it should succeed).
Documented with the trade-offs and the reasons for the trade-offs.
When the Toolkit generates code, it pulls from these patterns rather than improvising. You get a webhook handler that verifies HMAC signatures, deduplicates events, and writes to an outbox — not a webhook handler that just console.logs the payload. You get a multi-tenant query layer that scopes by tenant at the data-access level, not one that hopes the application layer remembered to filter.
(How our engineers use and interact with the tools of our AI Fintech Toolkit)
3. Guardrail layer: automated checks before code is allowed to live
This is the part that earns the name “guardrails”. Every piece of code that comes out of the Toolkit passes through a layered checklist before it reaches a human reviewer:
Static analysis, linting, and type-checking, tuned for the languages and frameworks we use most.
Secret and PII scanning, because LLMs have a charming habit of inventing API keys that look real and logging fields that shouldn't be logged.
Dependency policy, blocking unmaintained, vulnerable, or license-incompatible packages before they sneak into a project's dependencies.
AI-assisted review with reviewer prompts focused on fintech-specific concerns: amount precision, currency handling, idempotency, authorization checks, multi-tenant data isolation, access controls, and race conditions on shared resources.
Test scaffolding for both happy paths and failure cases — tests aren't an afterthought, they're a guardrail in their own right. Generated code arrives with unit and integration tests that prove its claims, including the cases where it's supposed to fail.
Documentation generation — every meaningful module ships with a README or inline docs explaining what it does, why, and how it integrates with the rest of the system. Code an auditor or new engineer can actually read.
The point is not to replace a human reviewer. The point is to make sure that by the time code reaches a human reviewer, the boring mistakes are already gone and they can focus on the interesting questions — domain decisions, architecture, product trade-offs.
4. Feedback layer: the toolkit gets smarter with every project
Every project teaches us something. A new edge case in a settlement flow. A subtle ambiguity in a card network's spec. A pattern that turned out to be more reusable than we expected.
We capture those lessons and feed them back into the Toolkit's patterns, prompts, and guardrails, so the next engineer starting a similar problem benefits from everything the previous one learned. Not by copying or reusing code, but by distilling the general lesson: the pattern, the pitfall, the principle.

The bigger picture
We think the interesting question for the next few years isn't “should engineers use AI?” — that's settled. The interesting question is how engineers use AI in domains where mistakes are expensive.
In fintech specifically, the answer can't be “let the model cook and hope”. It has to be a deliberate system: context the model can rely on, patterns it can build from, guardrails that catch what it gets wrong, and humans who own the final decision.
That's what the AI Fintech Toolkit is. Not a magic button, but a careful piece of engineering around a powerful, fast, and slightly reckless collaborator — turning that speed into something we can actually ship to production with our names on it.





